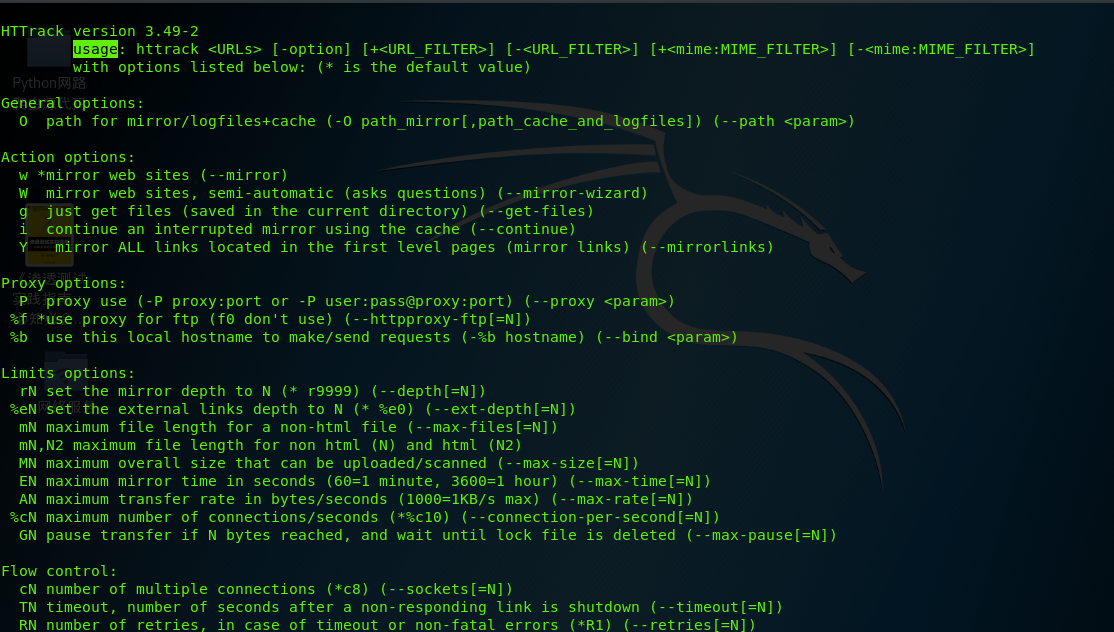
1、首先打开kali 中的这个工具 Web信息收集工具HTTrack ,会直接出现出现使用语法。
对于传统的像存在Robots.txt的网站,如果程序运行的时候不做限制,在默认的环境下程序不会把网站镜像,简单来说HTTPrack跟随基本的JavaScript或者APPLet、flash中的链接,对于复杂的链接(使用函数和表达式创建的链接)或者服务器端的ImageMap则不能镜像。
一般 不用挖的太深就能获取目标信息比如网站的物理地址,电话号码,电子邮箱地址,运营时间,商业关系,员工的姓名,与社会关系,以及公开的一些花絮。做渗透测试时一新闻其实也很重要,公司时长会公开一些自己感到骄傲的事情,这些报到中可能会泄露有用的信息,企业兼并服务器运转的情况
当然HTTrack有界面班版的支持Windows系统。
2、将一般的参数选项做个解释
Enter project name //输入项目名称, 程序会自动生成一个本地项目名称
Enter URLs (separated by commas or blank spaces) //欲抓取的网站地址
注意的是 Action中的参数操作:
(enter) 1 Mirror Web Site(s) 镜像网站2 Mirror Web Site(s) with Wizard 镜像网站和向导3 Just Get Files Indicated 只获得文件中声明的文件4 Mirror ALL links in URLs (Multiple Mirror) 在URl中所有的链接 多镜5 Test Links In URLs (Bookmark Test) 书签测试0 Quit 退出
Proxy (return=none) : 如果没有代理 不选择代理
You can define wildcards, like: -*.gif +www.*.com/*.zip -*img_*.zipWildcards (return=none) : //使用通配符下载,我直接回车
3、对HTTPrack的安装,如果是kali 则系统直接集成了该工具,LinuX或者其他麒麟系统没有的可以使用 apt -get install 安装
4、具体扒皮一个网站如下
首先 我拿自己的博客做个事例,通过对自己博客的克隆镜像来说明这个工具的使用方法。
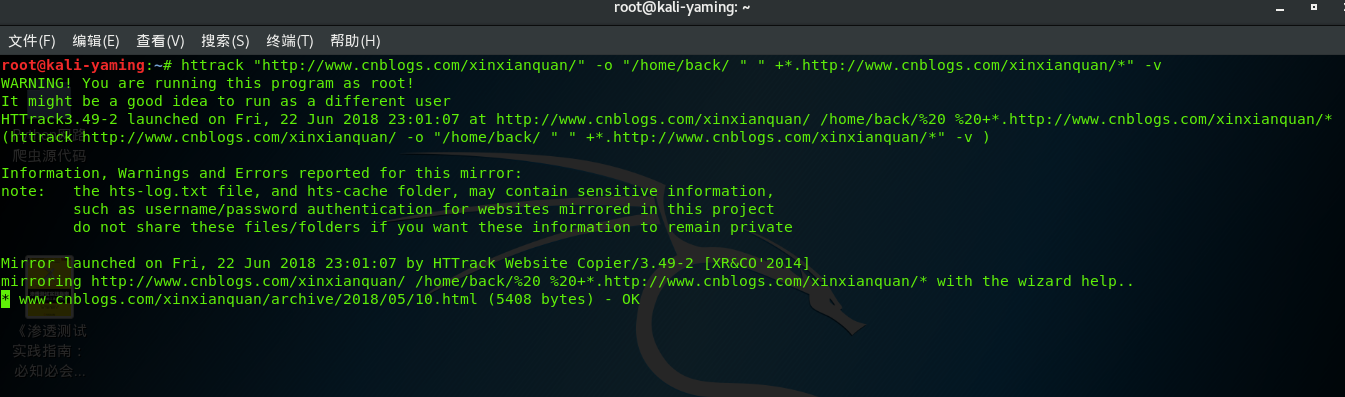
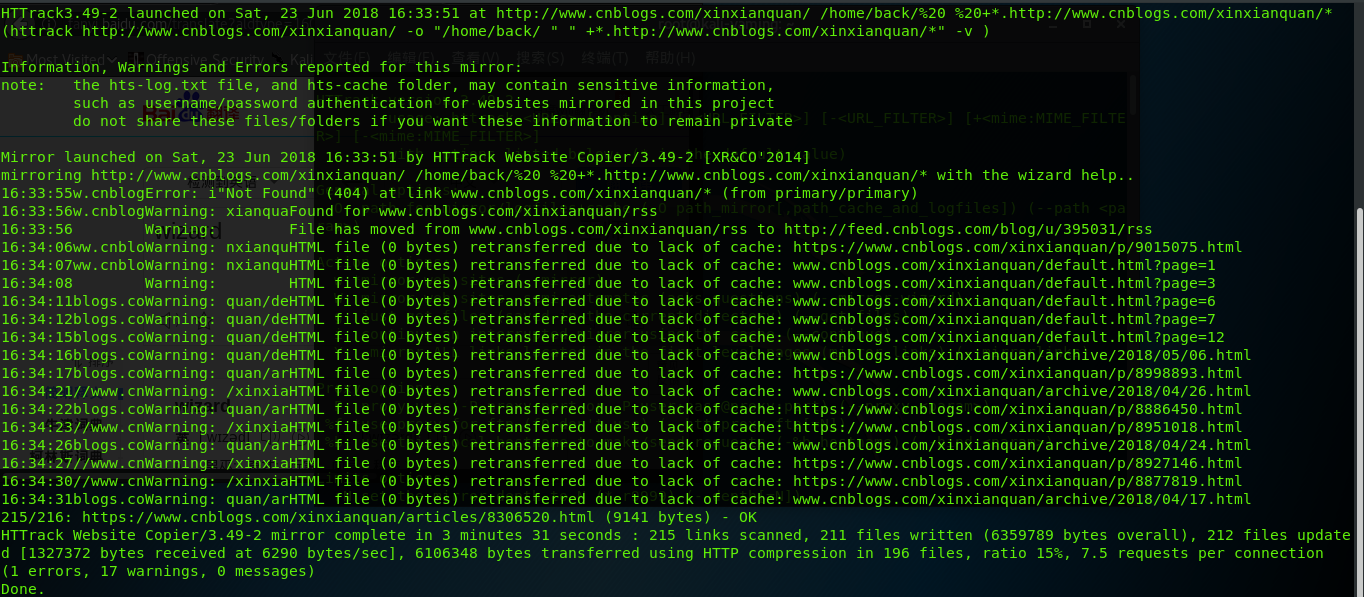
整个网页被扒下来之后,可能部分会出错,提示warning ,和errors信息,总共收集的网页链接个数,收集完之后如上所示。
打开其中一些扒下来的
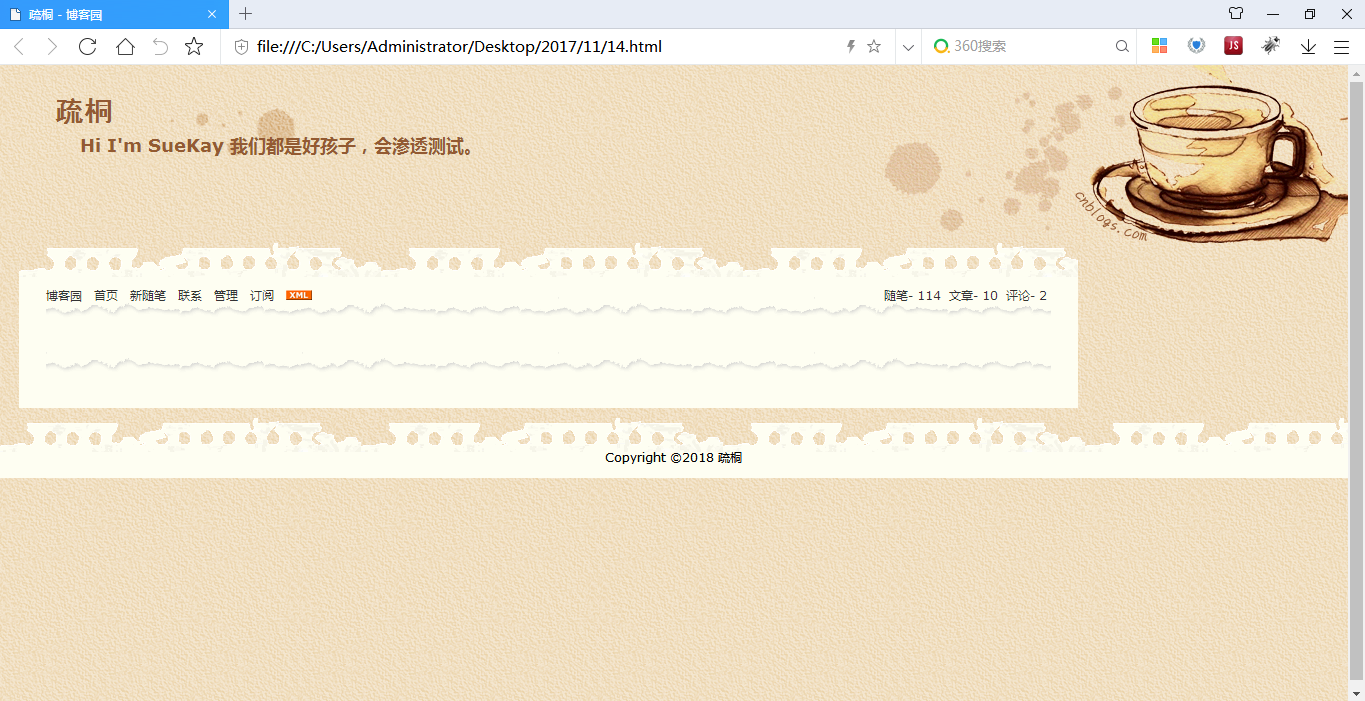
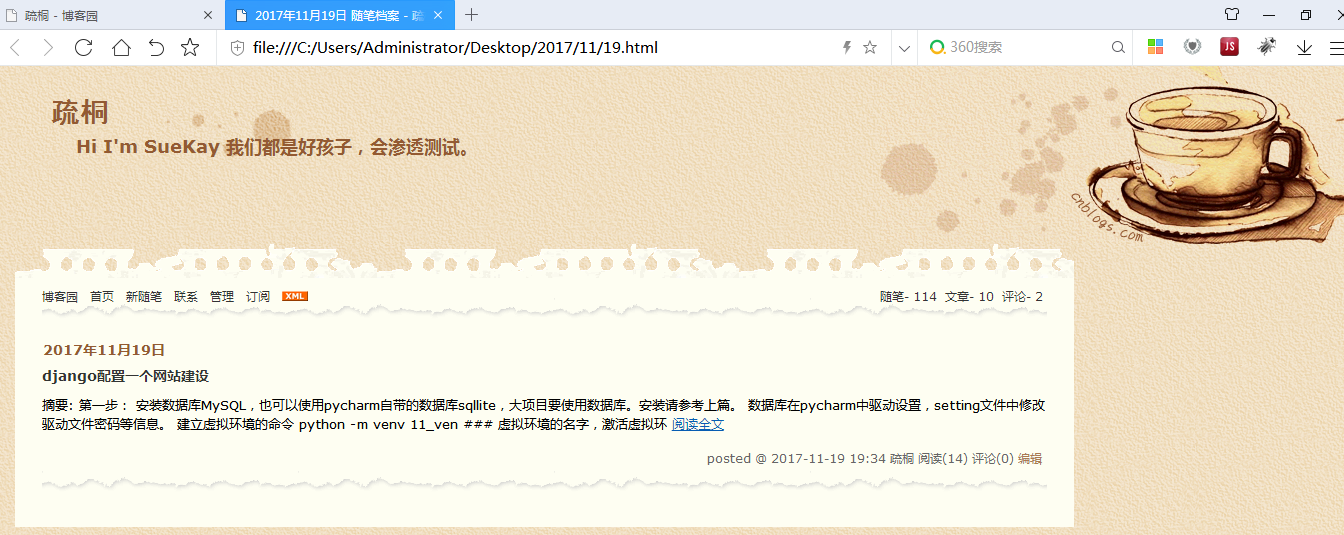
从上面的两个镜像的网页可以看出,首先在默认的设置下,镜像的网页会自动抠下网页的框架,博客的文章内容只是列出了梗概。不过通过设置过滤参数还可以对网站中链接的网址进行不同程度的过滤。
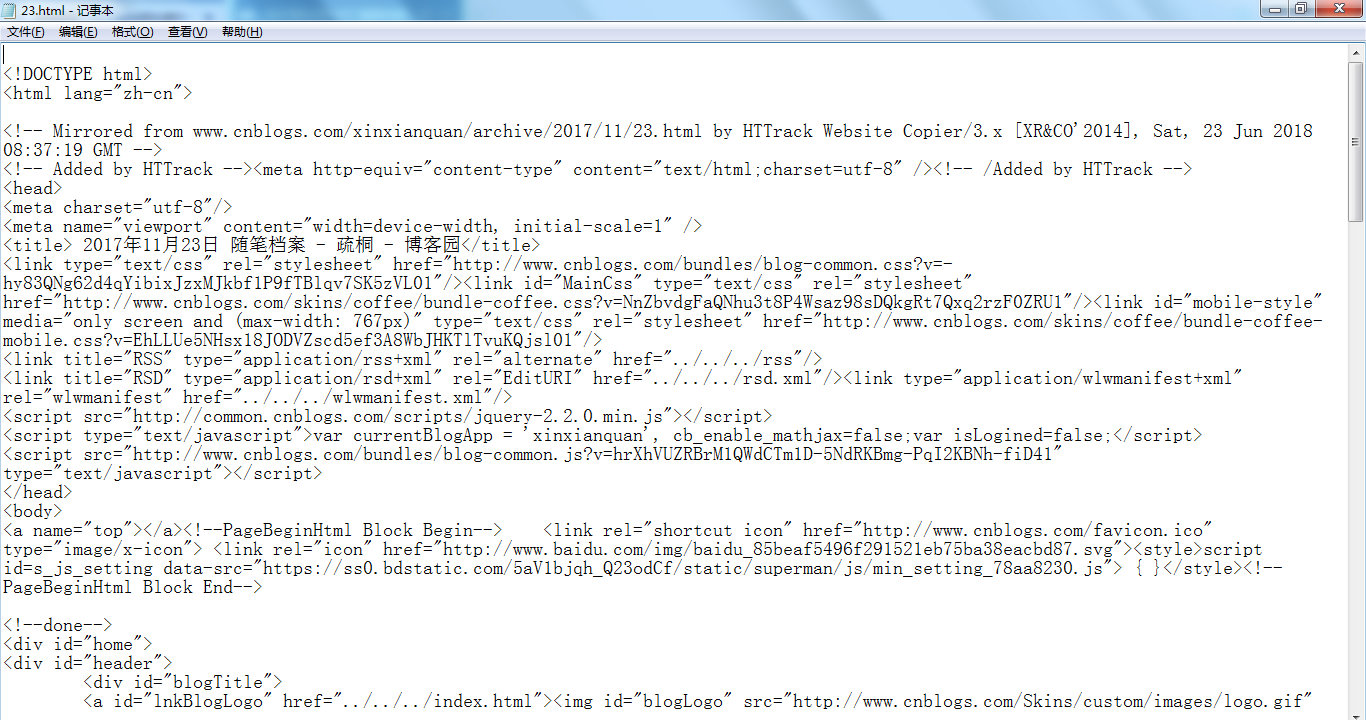
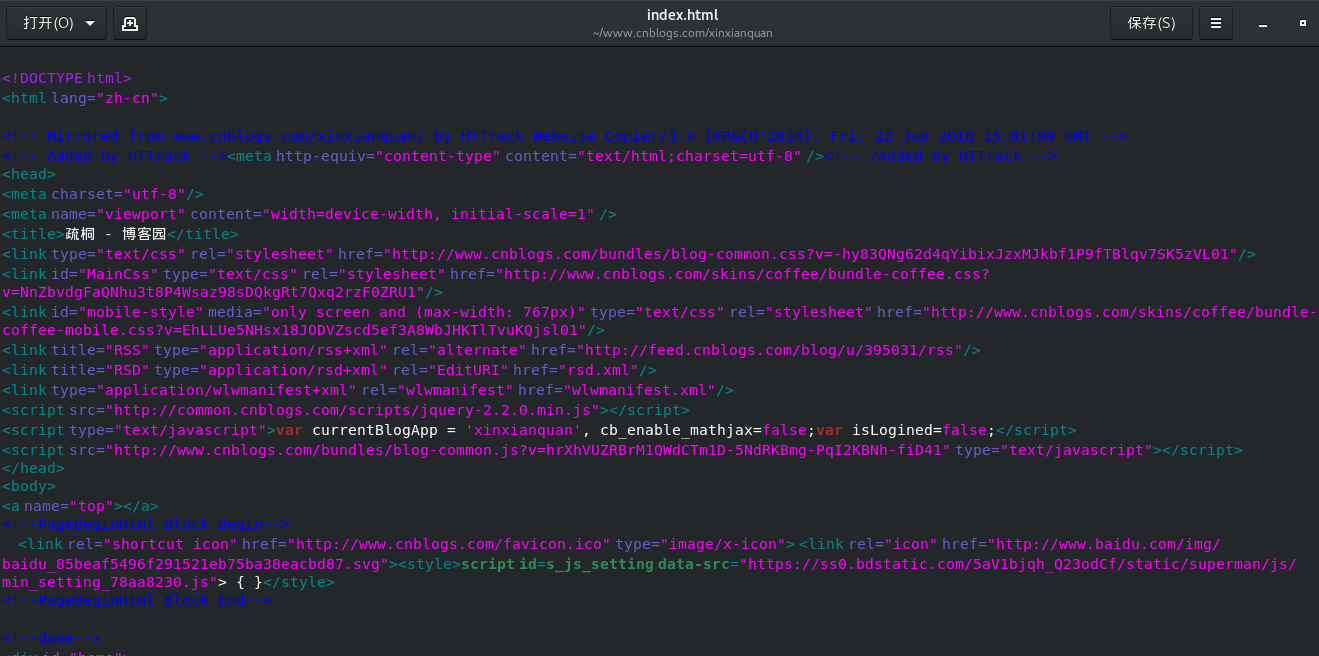
镜像下来的网页可以在离线的方式,进行渗透分析,传统的在网站主机上浏览网页,你浏览的和摸索的时间越多,活动可能被网站跟踪,哪怕是随意的浏览网站,也会被记录踪迹,只要属于目标资源,任何时候与之直接交互,都可能留下数字痕迹。
但是 在没有进行授权的时候千万不要使用该软件进行镜像网站上的网页,像部署了安全狗或者其他防火墙的专业软件可能会记录这种行为为攻击性质。所以我演示的是镜像我自己的网页。
之后如果测试网页存在注入漏洞,就可以对网站进行渗透测试
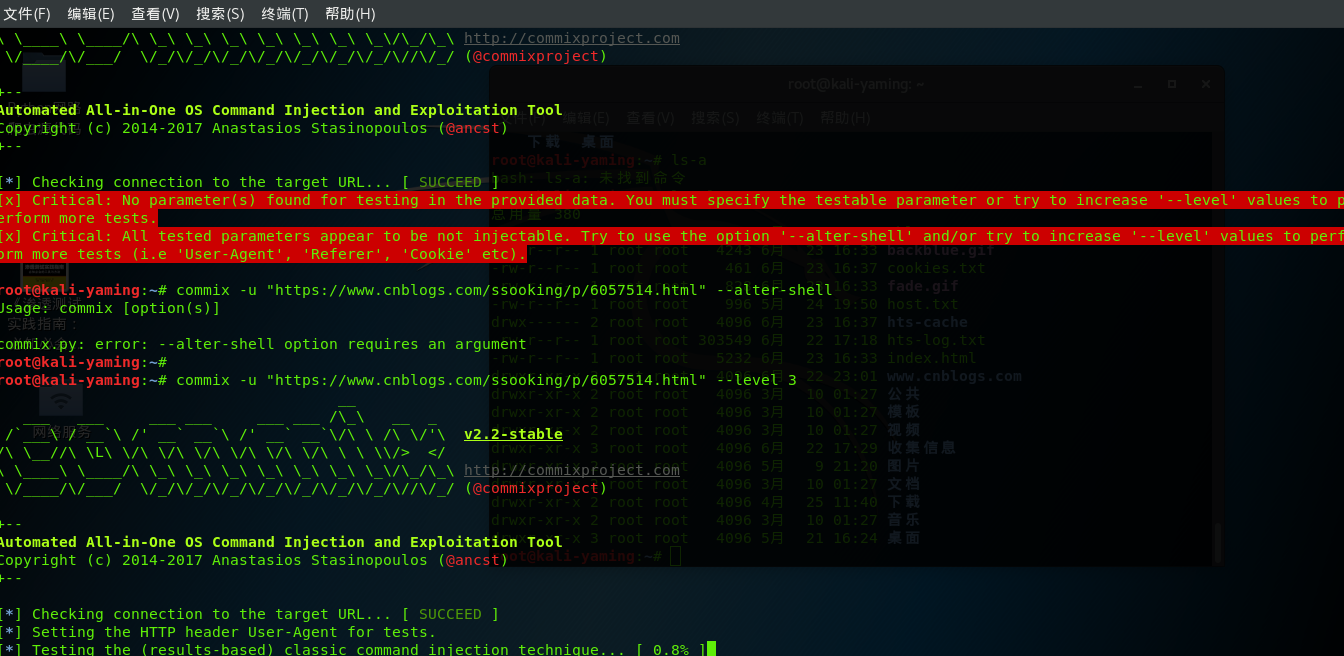
在自己主机上搭建一个网站之后,使用上面方式进行检测, 对主站的网页进行 渗透测试 使用工具 OWASP http://192.168.31.47/vulnerabilities/sqli/?id=1&Submit=Submit